摘要訊息 : 在帶有 NVIDIA 顯示卡的 CentOS 8 上配置深度學習環境.
0. 前言
由於學業原因, 我在網上租了一個帶有 NVIDIA T4 顯示卡的伺服器. 我自己完成配置之後, 覺得這個過程並沒有那麼順利, 所以就有了這一篇文章. 首先說一下我所租用的伺服器配置 :
- CPU : Intel Xeon Cascade Lake (2.5 GHz), 8 核心;
- 記憶體 : 32 GB;
- 顯示卡 : 1 顆 NVIDIA T4 顯示卡;
- 作業系統 : CentOS 8.2;
- Kernel : 4.18.0-305.3.1.el8.x86_64.
對於深度學習環境, 主要有 TensorFlow, PyTorch 和 Caffe. 這個教學主要是令大家伺服器上的顯示卡能夠正常使用, 不對這三個程式庫作任何介紹.
更新紀錄 :
- 2022 年 6 月 12 日進行第一次更新和修正.
1. 驅動程式下載
首先要確定你的顯示卡是 NVIDIA 的, 具體可以諮詢提供伺服器的服務商. 確定之後, 首先進入驅動程式下載的網站 : https://www.nvidia.com/Download/Find.aspx. 左側的選項是根據顯示卡的型號進行選擇, 右側是根據作業系統和 CUDA 版本進行選擇. 對於左側, 大家按照自己的顯示卡型號選擇即可.

這個是我的選擇. 對於右側的選項, 我們的作業系統是 CentOS 8 Red Hat, 因此我們選擇 Linux 64-bit RHEL 8. 如果你的作業系統有不同, 那麼根據自己的作業系統進行選擇. 第二個選項是 CUDA Toolkit, 我們是最新的作業系統, 所以我們選擇最新的版本 11.2, 這是截至發文為止的最新版本. 對於語言, 大家根據自己的喜好進行選擇. 最後一個選項保持預設 All :

點擊 SEARCH 之後, 下面就會出現下載的選項, 可能會存在多個版本, 選擇最新的版本即可 :
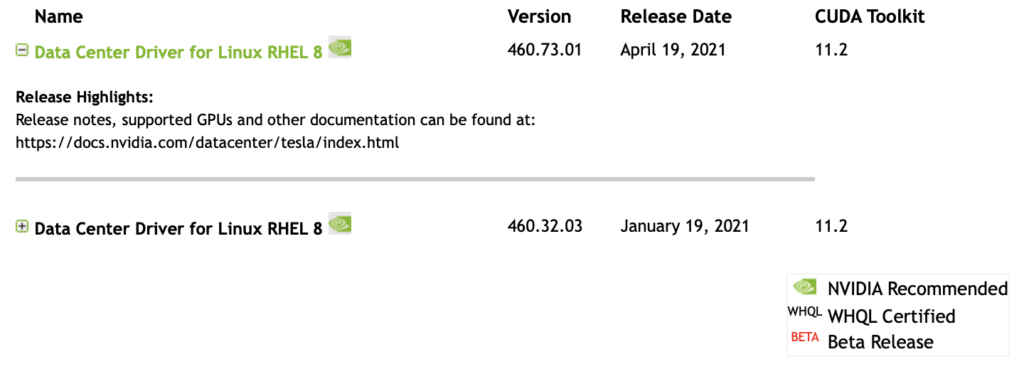
點擊對應的 Name 之後, 進入下載網頁, 點擊下載可以獲取到下載地址 : https://tw.download.nvidia.com/tesla/460.73.01/nvidia-driver-local-repo-rhel8-460.73.01-1.0-1.x86_64.rpm. 這是截至發文為止最新版本的下載地址. 你可以下載到本機之後上載到伺服器, 或者直接在伺服器上運作指令 : wget https://tw.download.nvidia.com/tesla/460.73.01/nvidia-driver-local-repo-rhel8-460.73.01-1.0-1.x86_64.rpm.
2. CUDA 下載
進入下載頁面 : https://developer.nvidia.com/cuda-downloads, 根據作業系統進行選擇 :
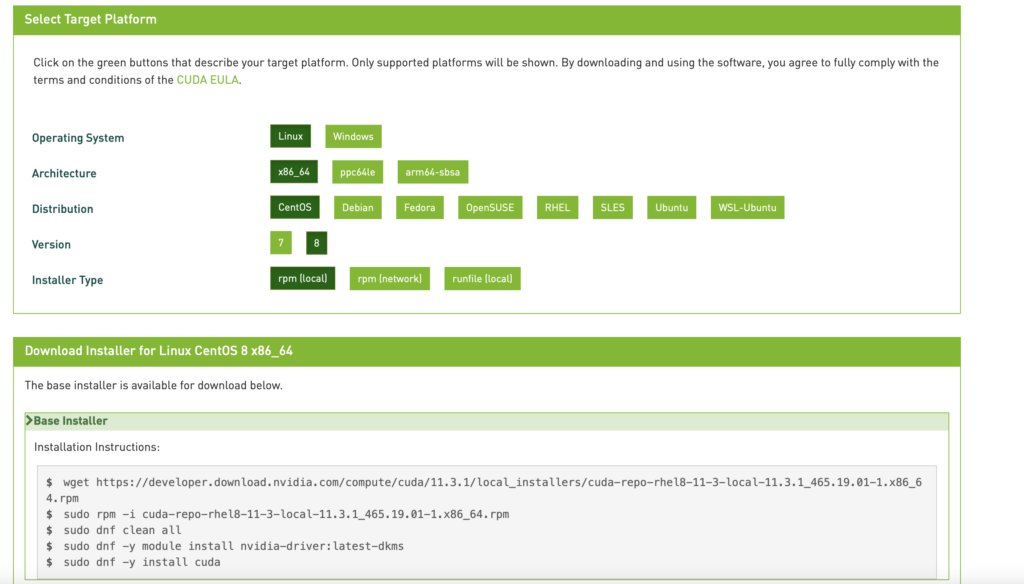
下面就得到了安裝的指令, wget 之後就是下載的網址. 直接拷貝帶有 wget 這一行在伺服器上執行這個指令即可.
3. cuDNN 下載
cuDNN 的下載是需要註冊帳戶的, 還需要填寫一個調查. 這個大家根據頁面提示填寫即可 : https://developer.nvidia.com/rdp/cudnn-download. 登陸之後, 勾選 I Agree To the Terms of the cuDNN Software License Agreement, 然後選擇 Download 最新版本. 截至發文為止, 最新版本為 Download cuDNN v8.2.1 (June 7th, 2021), for CUDA 11.x :

我們下載的是 cuDNN Library, 我們的是 CentOS 8, 64 位元組版本的, 所以選擇 cuDNN Library for Linux (x86_64). 截至發文為止的最新版本為 https://developer.nvidia.com/compute/machine-learning/cudnn/secure/8.2.1.32/11.3_06072021/cudnn-11.3-linux-x64-v8.2.1.32.tgz. 因此在伺服器上, 我們可以直接執行指令 wget https://developer.nvidia.com/compute/machine-learning/cudnn/secure/8.2.1.32/11.3_06072021/cudnn-11.3-linux-x64-v8.2.1.32.tgz.
4. 環境配置
現在, 我們已經將所有需要的軟體下載完成了, 接下來對於 RPM 包直接匯入, 壓縮包直接解壓縮 :
rpm -i nvidia-driver-local-repo*.x86_64.rpm
rpm -i cuda-repo*.x86_64.rpm
tar -zxvf cudnn*.tgz在安裝之前, 我們升級一下作業系統自帶的軟體 (這一步可以不需要) : dnf update -y. 我是執行了這一步的, 但是不同伺服器提供商提供的伺服器可能是稍有不同的, 是否需要執行升級指令, 大家可以自行判斷.
然後我們正式開始配置. 首先安裝驅動程式 dnf install -y cuda-drivers, 這一步完成之後需要重啟一下 : reboot. 重新啟動作業系統之後, 安裝 CUDA : dnf install -y cuda.然後需要將 CUDA 添加到環境變數 : vim ~/.bashrc, 然後按 Shift + G 定位到檔案末尾, 按下 i 進入編輯模式, 在最後添加 :
export LD_LIBRARY_PATH=/usr/local/cuda-版本號/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
export PATH="$PATH:/usr/local/cuda/bin"上面的版本號需要自己查詢, 截至發文為止的版本號為 11.3, 因此可以替換為 11.3. 具體的查詢方法是進入 /usr/local 檔案夾 : cd /usr/local, 然後使用 ll 指令列出全部檔案和檔案夾, 大家可以看一下帶有 cuda-xx.xx 這個檔案夾, 直接複製版本號替換即可. 完成之後按下 esc 退出編輯模式後, 按下 : 並且輸入 wq! 保存, 然後刷新一下 : source ~/.bashrc. 接下來我們將 cuDNN 對應的標頭檔複製到對應的檔案夾中, 並且給予一定的權限 :
cp cuda/include/cudnn.h /usr/local/cuda/include/
cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/ -d
chmod a+r /usr/local/cuda/include/cudnn.h
chmod a+r /usr/local/cuda/lib64/libcudnn*如果之前你進入了 /usr/local 檔案夾, 這裡你需要注意一下, 回到你剛剛使用 wget 指令下載驅動程式, CUDA 和 cuDNN 的檔案夾中. 現在, 大家可以試一下 nvcc -V 指令, 正常來說, 會有下面的輸出 :

nvcc -V 回傳結果然後使用指令 nvidia-smi 查看一下 GPU :
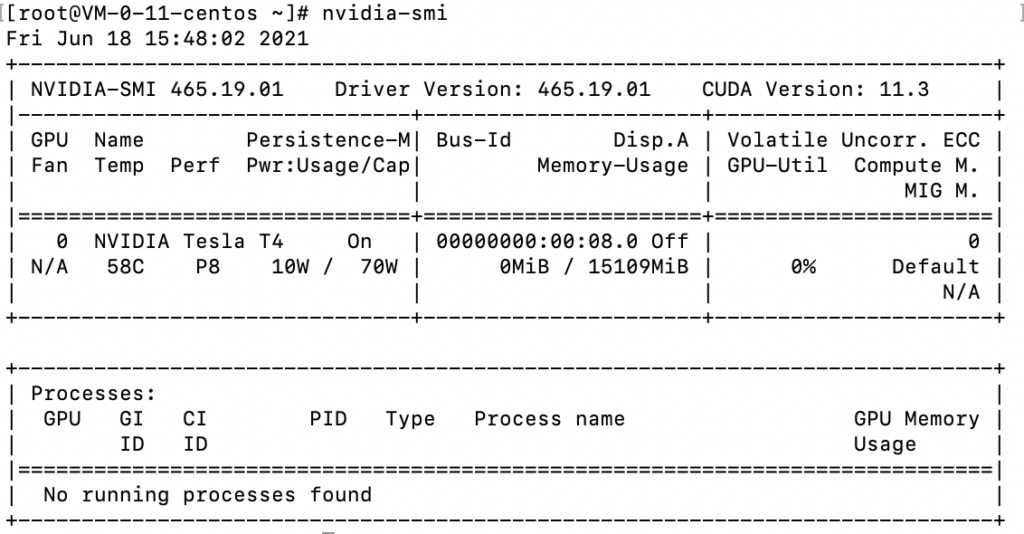
nvidia-smi 回傳結果如果是下面的結果 :

nvidia-smi 不正確結果那就是有問題. 我們首先安裝需要的軟體 : dnf install -y kernel-devel dkms, 然後輸出指令 ls /usr/src | grep nvidia 可以得到驅動的版本號 :
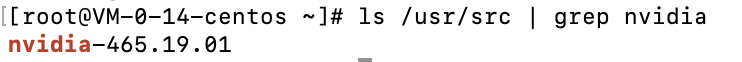
ls /usr/src | grep nvidia 回傳結果然後把後面的版本號 465.19.01 複製下來, 輸入指令 dkms install -m nvidia -v 465.19.01, 後面的版本號要和你自己安裝的對應, 否則仍然會產生錯誤. 安裝完成之後, 再次輸入指令 nvidia-smi 應該就可以看到顯示卡了.
5. 安裝 TensorFlow 和 Keras
其實安裝非常簡單, CentOS 8 自帶有 Python 3, 直接執行指令
pip3 install --upgrade pip
pip3 install tensorflow-gpu keras
pip3 install h5py numpy pillow安裝之後, 可以創建一個檔案 test.py : vim test.py, 輸入以下程式碼 :
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))保存退出之後, 運作程式碼 : python3 test.py. 我們安裝的預設版本是 TensorFlow 2, 所以上面程式碼可以和 TensorFlow 2 相容. 最終的結果是 :
2021-06-18 16:12:11.624018: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0 2021-06-18 16:12:12.724656: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-06-18 16:12:12.726676: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1 2021-06-18 16:12:12.760898: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:12.761773: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties: pciBusID: 0000:00:08.0 name: NVIDIA Tesla T4 computeCapability: 7.5 coreClock: 1.59GHz coreCount: 40 deviceMemorySize: 14.75GiB deviceMemoryBandwidth: 298.08GiB/s 2021-06-18 16:12:12.761815: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0 2021-06-18 16:12:12.767714: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11 2021-06-18 16:12:12.767797: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11 2021-06-18 16:12:12.768851: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10 2021-06-18 16:12:12.769151: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10 2021-06-18 16:12:12.769684: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11 2021-06-18 16:12:12.770638: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11 2021-06-18 16:12:12.770828: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudnn.so.8 2021-06-18 16:12:12.770938: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:12.771830: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:12.772626: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0 2021-06-18 16:12:12.772666: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0 2021-06-18 16:12:13.356259: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix: 2021-06-18 16:12:13.356305: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264] 0 2021-06-18 16:12:13.356323: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1277] 0: N 2021-06-18 16:12:13.356534: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:13.357270: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:13.358095: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-06-18 16:12:13.358881: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1418] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 13805 MB memory) -> physical GPU (device: 0, name: NVIDIA Tesla T4, pci bus id: 0000:00:08.0, compute capability: 7.5) 2021-06-18 16:12:13.360139: I tensorflow/core/common_runtime/direct_session.cc:361] Device mapping: /job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: NVIDIA Tesla T4, pci bus id: 0000:00:08.0, compute capability: 7.5 MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0 2021-06-18 16:12:13.360892: I tensorflow/core/common_runtime/placer.cc:114] MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0 a: (Const): /job:localhost/replica:0/task:0/device:GPU:0 2021-06-18 16:12:13.360916: I tensorflow/core/common_runtime/placer.cc:114] a: (Const): /job:localhost/replica:0/task:0/device:GPU:0 b: (Const): /job:localhost/replica:0/task:0/device:GPU:0 2021-06-18 16:12:13.360927: I tensorflow/core/common_runtime/placer.cc:114] b: (Const): /job:localhost/replica:0/task:0/device:GPU:0 2021-06-18 16:12:13.361232: I tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2494140000 Hz [[22. 28.] [49. 64.]]
前面我們可以看到, 有很多個程式庫的載入都是 successful 的. 最後運算的時候, 用的是 /job:localhost/replica:0/task:0/device:GPU:0. 如果看到 GPU 就是成功了, 如果是 CPU, 那麼就是沒有成功. 首先看一下前面是否有程式庫載入不成功. 最開始, 我有一個名稱為 libcudnn.so.8 的程式庫載入不成功, 當時的提示為 Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory. 實際上就是某個程式庫沒有安裝. 我們在 https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/ 上搜尋對應的 RPM 包, 我們安裝的是 CUDA 11.3, 所以對應了下面圖片中這個 RPM 包

截至發文為止, 最新的下載地址為 https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/libcudnn8-8.2.1.32-1.cuda11.3.x86_64.rpm, 所以我們輸入指令下載到伺服器 : wget https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/libcudnn8-8.2.1.32-1.cuda11.3.x86_64.rpm. 然後匯入 RPM 包 : rpm -i libcudnn*.rpm. 最後安裝 : dnf install -y libcudnn8. 再次運作剛剛的程式, 你就會發現程式庫載入不成功的提示會消失, 後面的運作設備不是 CPU, 而是 GPU.
自創文章, 原著 : Jonny. 如若閣下需要轉發, 在已經授權的情況下請註明本文出處 :







